台式电脑,笔记本电脑,手机,平板无限畅享。
当美国总统特朗普周三对几乎所有美国贸易伙伴征收关税时,他对中国也发表了强硬言论。
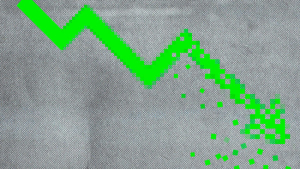
美股创2020年以来最差单周表现。中国反击特朗普关税,贸易战骤然升级引发华尔街史诗级的两日抛售,市值蒸发逾6万亿美元。
美国上市中概股普遍遭遇重挫,阿里巴巴和京东股价均下跌逾9%;这一反制举措可能会使市场刚刚显现的复苏势头戛然而止。
中国对特朗普的“解放日”关税发起反击,将自4月10日起对所有从美国进口的商品加征34%的关税,金融市场抛售随之加剧。
特朗普一直梦想着通过关税让美国的工厂和城镇重焕活力。但对关税将损害经济的担忧已重挫股市。
受关税影响,苹果公司的成本即将大幅上升。这家全球市值最高的公司现在面临的最大问题是,是让消费者为此买单,还是让投资者买单。
依然还有很多课要补。
韩国宪法法院现有8名法官,如果有6人赞成,弹劾案即获通过;根据宪法尹锡悦被罢免,韩国将在60天内,即最迟6月3日举行总统选举。
美国股市周四遭遇2020年以来最大单日跌幅,投资者担心总统特朗普的新关税计划将引发全球报复,损害美国经济。与此同时,美元兑其他主要货币汇率跌至今年最低水平。
新的不确定性的开始?